
Posiblemente usas dd para copiar/restaurar tarjetas sd/microsd pero lo cierto es que podemos darle muchos más usos combinado con hd, xxd, …
Vamos a analizar como se estructura un mod formato protracker. Se trata de archivos que suelen llevar la extensión .mod y que son archivos de sonido.
Estos archivos contienen tanto los samples, como las instrucciones de cuando y como se reproducirán esos samples, nombres de los samples, nombre del modulo de sonido, …
Vamos a extraer con dd los nombres de los samples que contiene un archivo mod y los propios samples.

Vamos a ello. Para probar vamos a bajar este pack de un par de archivos mod que nos van a servir de ejemplo: mods.zip
Podemos bajarlo y descomprimirlo así:
$ wget "https://56k.es/wp-content/uploads/2021/01/mods.zip" $ unzip mods.zip $ cd mods
Una vez descomprimido vamos a utilizar el archivo llamado ancient_days_.mod y a comenzar a usar milkytracker para reproducirlo y ver que contenido tiene.
Podemos instalar milkytracker así en Debian:
# apt-get install milkytracker
Utilizando dd podemos extraer el nombre de la canción. Este nombre está escrito en los primeros 20 bytes del archivo mod en formato protracker y por tanto está entre el byte 0 y el byte 20.
El nombre del modulo musical (el de la canción) siempre estará entre esos 20 bytes y si no los rellena enteros estará rellenado con null.
Veamos si es cierto:
$ dd skip=0 count=20 bs=1 status=none iflag=skip_bytes,count_bytes if=ancient_days_.mod | hexdump -e '"\nNombre canción: " 20/1 "%c" "\n" "\n"'

Otra forma es en vez de usar hexdump y dd directamente usar solamente xxd así:
$ xxd -g 1 -l 20 -c 20 ancient_days_.mod
Soltará un churro de 20 bytes como este:
00000000: 61 6e 63 69 65 6e 74 20 64 61 79 73 2e 2e 2e 2d 6c 7a 64 00 ancient days...-lzd.
- La primera columna es la posición. En este caso de 0 a 20 bytes y por tanto muestra 00000000:
- La segunda columna muestra el churro en hexadecimal: 61 6e 63 69 65 6e 74 20 64 61 79 73 2e 2e 2e 2d 6c 7a 64 00
- La tercera columna lo muestra en ascii: ancient days…-lzd.
Si nos fijamos el nombre es ancient days. En este caso aparte del nombre el autor/a del modulo ha añadido -lzd
Si probamos con otros módulos veremos otros títulos de otros módulos tal que así:
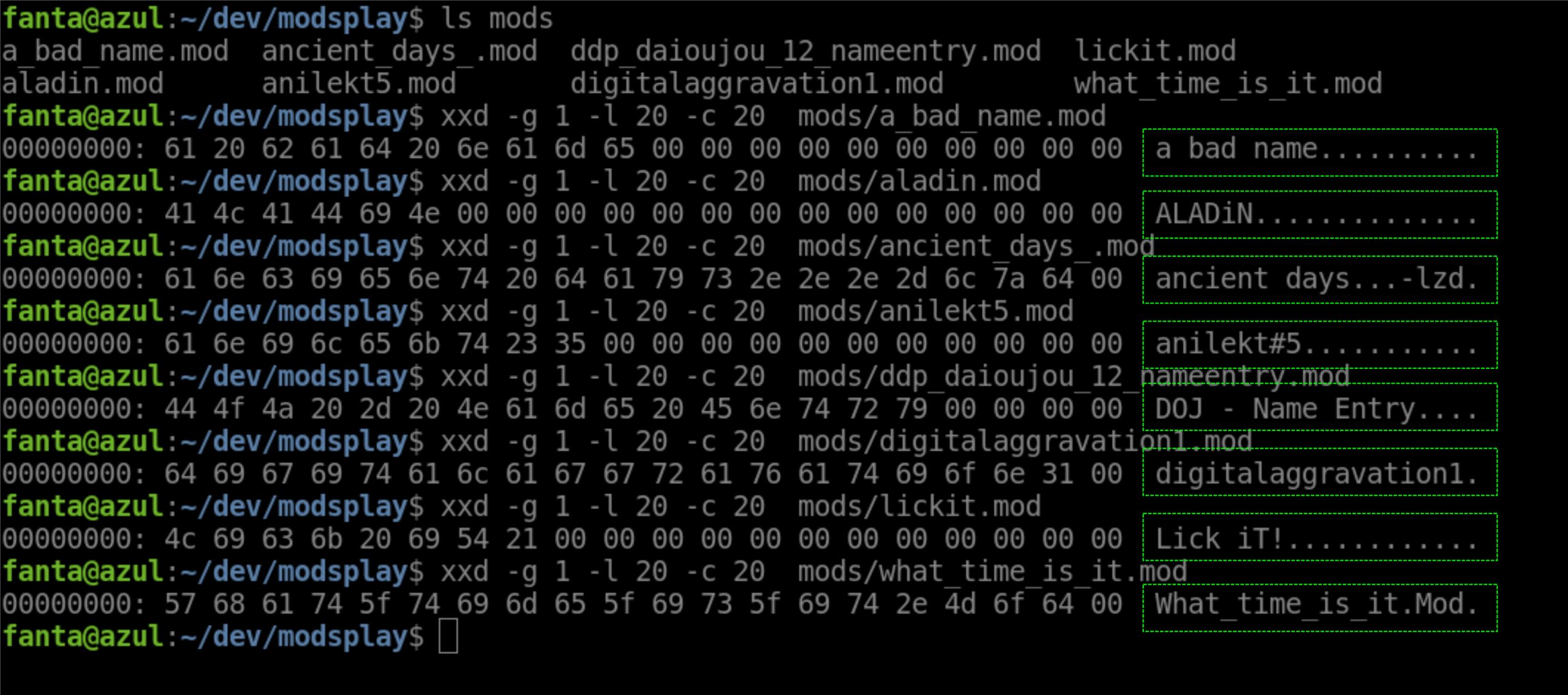
Ya sabemos el nombre del modulo musical ya que sabemos que está en los bytes 0-20
Ahora vamos a por los nombres de los samples.
Este script en bash nos puede servir para recorrer las cabeceras de samples y extraer el nombre de los samples utilizados en el modulo de sonido. Se ejecutaría así "bash nombrescript.sh nombre.mod" y el código es el siguiente:
#!/bin/bash
position=20
for i in $(seq 1 31);
do
dd skip=$position count=22 bs=1 status=none iflag=skip_bytes,count_bytes if=$1 | xxd -c 22 | awk '{print $13}'
let position=position+30
done
Si lo guardamos en un archivo llamado sample-name.sh se puede ejecutar como se ve en la captura:
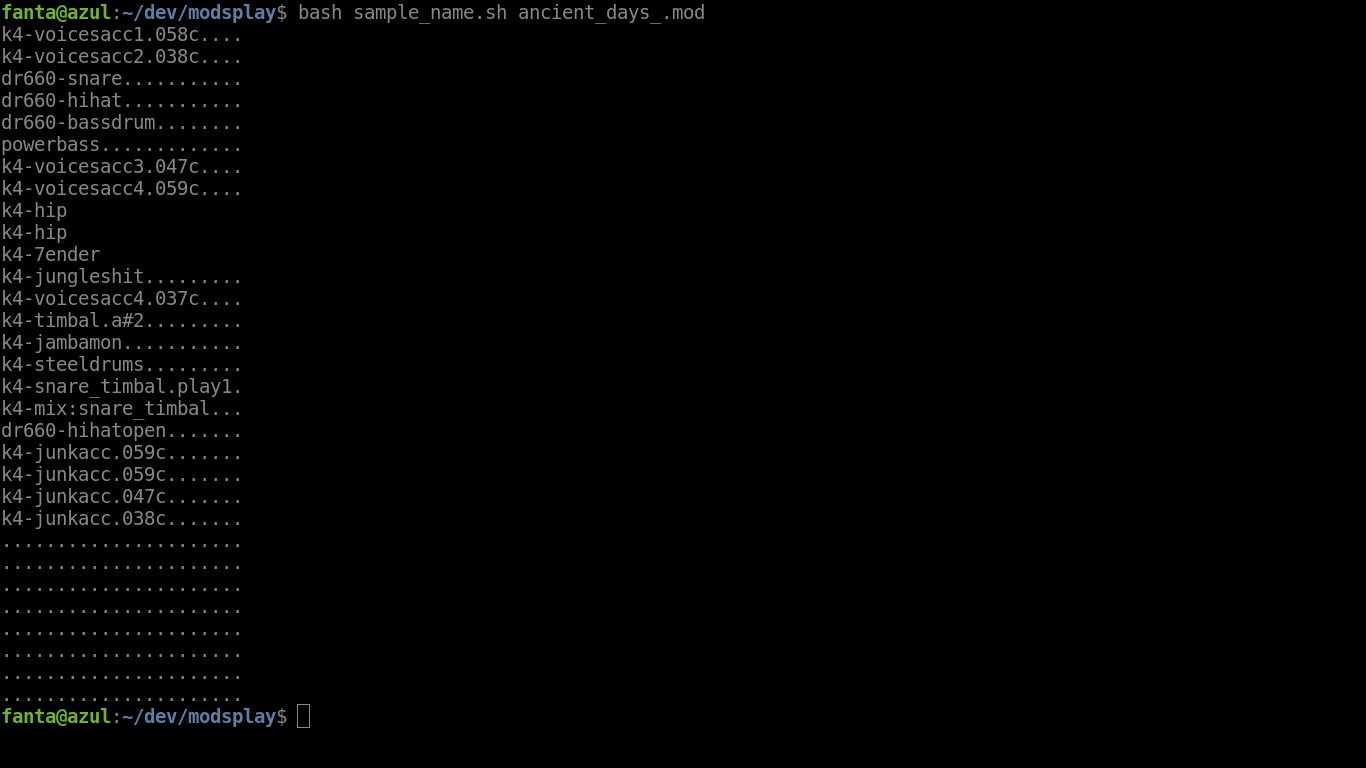
Tras los primeros 20 bytes encontraremos las cabeceras de los samples. El formato protracker de mods soporta hasta 31 samples y por tanto encontraremos 31 cabeceras que ocupan cada una de ellas 30 bytes.
cabecera sample1 - offset 20 cabecera sample2 - offset 50 cabecera sample3 - offset 80 cabecera sample4 - offset 110 cabecera sample5 - offset 140 ... cabecera sample30 - offset 890 cabecera sample31 - offset 920
Las cabeceras de samples contienen mucho más que el nombre. Si miramos chuletas sobre el formato protracker veremos que de esos 30 bytes solamente para el nombre del sample se usan 22. Es por eso que nosotros/as a dd le indicamos con count 22.
El tamaño del sample estará en la cabecera de cada uno de ellos. Esto es importante para poder luego localizar cada sample (el contenido del sample) y poder extraerlo.
Veamos como se estructuran las cabeceras de los samples. Concretamente del sample 1:
Offset Bytes Description
------ ----- -----------
20 22 Samplename for sample 1. Pad with null bytes.
42 2 Samplelength for sample 1. Stored as number of words.
Multiply by two to get real sample length in bytes.
44 1 Lower four bits are the finetune value, stored as a signed
four bit number. The upper four bits are not used, and
should be set to zero.
Value: Finetune:
0 0
1 +1
2 +2
3 +3
4 +4
5 +5
6 +6
7 +7
8 -8
9 -7
A -6
B -5
C -4
D -3
E -2
F -1
45 1 Volume for sample 1. Range is $00-$40, or 0-64 decimal.
46 2 Repeat point for sample 1. Stored as number of words offset
from start of sample. Multiply by two to get offset in bytes.
48 2 Repeat Length for sample 1. Stored as number of words in
loop. Multiply by two to get replen in byt
Esos 30 bytes usan 22 bytes para el nombre y si nos fijamos luego utilizan 2 más para Samplelength (el tamaño del sample). La peculiaridad es que el valor que esté fijado en esos 2 bytes tendrá que ser multiplicado por 2 para obtener el tamaño del sample en bytes.
Vamos a ver como extraer el primer sample del archivo que estamos analizando.
Para hacer se han de conocer 3 valores:
- La longitud de patterns de la canción. Conocido como Songlength. (offset 950, bytes 1)
- En que byte comienza a almacenarse el data pattern (offset 1084, cada data pattern ocupará 1024)
- El tamaño en bytes del sample.
La longitud de patterns de la canción podemos obtenerla así ya que estará ocupando 1 byte en el byte 950 del archivo mod (los valores estarán entre 1 y 128 que el maximo de patterns que se pueden usar en un modulo mod):
$ dd skip=950 count=1 bs=1 status=none iflag=skip_bytes,count_bytes if=ancient_days_.mod | hd
Eso nos dará en hexadecimal el valor: 12
Lo podemos convertir a decimal así:
$ echo "ibase=16; 12"|bc
Nos dará 18. 18 patterns tiene ese modulo de sonido.
Sabemos que tiene 18 patters y sabemos que estos comienzan a almacenarse ocupando 1024 bytes desde el byte 1084.
Con esto ya podemos calcular en que parte del modulo estará almacenado el primer sample.
1084 + (18 * 1024) = 19516
Sabemos que hemos de sumar a 1084 (el offset en el que comienza a almacenarse el data pattern) 18432 bytes que es lo que nos da de multiplicar 1024 * 18 patterns que tiene el modulo.
El primer sample estará almacenado por tanto en 19516 . ¿Pero cuanto ocupa el primer sample?
Lo miramos en el offset 42 (ya que el primer sample comienza en el offset 20 y el nombre ocupa 22 bytes) y tendría que estar ocupando 2 bytes (o no ocupandolos si no se ha almacenado un primer sample).
$ dd skip=42 count=2 bs=1 status=none iflag=skip_bytes,count_bytes if=mods/ancient_days_.mod | hd
Nos sacará esto que se ve en la captura:

Nos saca el valor hexadecimal 0953 que en decimal es 2387. Hemos de recordar que ese valor para obtenerlo en bytes reales hemos de multiplicarlo por 2 de modo que nos da un valor de: 4774 bytes.
Ya tenemos lo necesario para extraer el sample1 !
El primer sample estará en el offset 19516 ocupando 4774 bytes. Lo podemos exstraer así:
$ dd skip=19516 count=4774 bs=1 status=none iflag=skip_bytes,count_bytes if=mods/ancient_days_.mod of=k4-voicesacc1
He colocado como nombre de salida k4-voicesacc1

El archivo de salida podemos cargarlo como sample en milkytracker o podemos abrirlo con milkytracker y que esté cargado: milkytracker k4-voicesacc1
Si en milkytracker vamos a mostrar el editor de samples podemos escucharlo con diferentes velocidades de muestreo usando las teclas del teclado. Allí podemos exportarlo a wav si queremos y eso ocupará más al final de cuentas pero tendrá las cabeceras y datos necesarios para poder abrirse con vlc, audacity sin tener que importarlo como datos en bruto, etc…
En fin. Esto es más o menos como funciona un archivo mod o más bien, la forma en la que se estructura y se almacena la información.
No necesitamos en realidad nada más que un editor hexadecimal para hacer todo esto si tenemos a mano la chuleta de como es el formato binario protracker.
En futuras entradas veremos quizás como usar el editor «le» con el argumento -h para abrir archivos y poder exportar los bloques seleccionados. De esa forma se hace todo visualmente.
Saludos cordiales.
Más información de interés:
- Formato protracker: coppershade.org/articles/More!/Topics/Protracker_File_Format/
- Formato protracker: ftp.modland.com/pub/documents/format_documentation/FastTracker%202%20v2.04%20%28.xm%29.html
- Formato XM: web.archive.org/web/20100921225940/http://io.debian.net/~tar/debian/xmp/xmp-2.7.1/docs/formats/Ultimate_Soundtracker-format.txt