
La base de datos de bichos de clamav se distribuye con extensión: cvd
Desde aquí puede descargarse sin necesidad de bajar el engine (motor) antivirus: www.clamav.net/downloads
En realidad se trata de un archivo tar.gz con una cabecera de 512 bytes.
Eso significa que en realidad andamos ante un paquete tar (la utilidad GNU tar empaqueta, no comprime necesariamente) que luego ha sido comprimido.
Pero con 512 bytes al principio que son la cabecera para que el tipo de archivo cvd sea reconocido como en mi caso así:
Clam AntiVirus database 25 Nov 2019 08-56 -0500, version 59, gzipped
¿Quién y como se puede reconocer un tipo de archivo?
Evidentemente no por la extensión en su nombre de archivo. Para ello se usa la magia.
Para reconocer un tipo de archivo puedes usar la maravillosa herramienta «file».
Aquí por ejemplo se encuentra «la magia» que nos dice como se reconoce un tipo de archivo cvd por su cabecera y no por su extensión en el nombre: github.com/file/file/blob/master/magic/Magdir/fsav
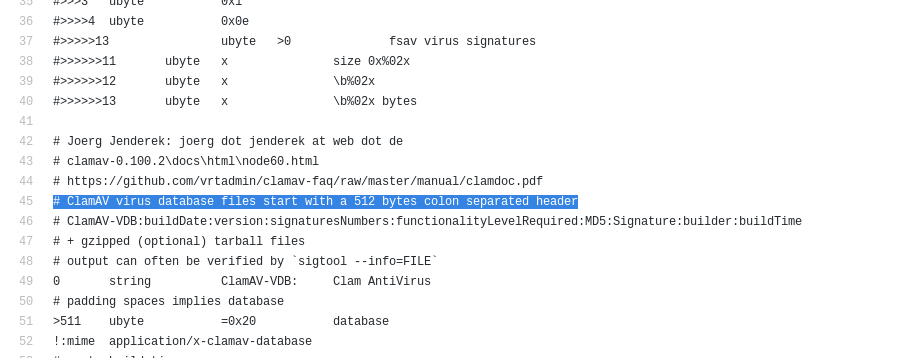
Todas esas «pistas» nos permiten saber que al bajar el main.cvd (la base de datos de firmas del antivirus clamav) prácticamente estamos ante un tar de toda la vida comprimido en gzip (tar.gz).
Demo Time – Bajar, quitar cabecera y descomprimir main.cvd
La forma de descargar el fichero con las firmas de los bichos y luego confirmar que se trata de eso puede hacerse así si andas en una debian o distro similar:
# apt update # apt install wget file ncdu le -y $ wget "http://database.clamav.net/main.cvd" $ file main.cvd
Veremos algo así posiblemente:

Usando dd para algo más que grabar en la una tarjeta SD o microSD Raspbian
Ahora es cuando utilizamos dd para lo que se ha de utilizar. Para extraer chunks, omitir chunks, … posicionarnos en una zona y leer y sacar.
En este caso vamos a ver como extraer solamente la cabecera que nos está impidiendo que el archivo cvd sea reconocido como un simple tar.gz.
$ dd skip=0 count=512 bs=1 status=none iflag=skip_bytes,count_bytes if=main.cvd of=main.cvd.header
Esto lo que hace es básicamente tener un origen (input file, if) y un destino (output file, of). De modo que leemos desde main.cvd y extraemos a un archivo llamado main.cvd.header el chunk de bytes que queremos.
Le estamos diciendo que el bytestream es de 1 byte y que vamos a contar hasta 512 bytes y que con skip no vamos a saltar nada. Eso en cristiano es pilla solo los primeros 512 bytes del archivo main.cvd y nos los deja guardados en un archivo llamado main.cvd.header.
Eso no nos vale para mucho. Lo que vale es extraer justo lo inverso. Se puede hacer así para omitir esos 512 bytes de cabecera:
$ dd if=main.cvd of=main.cvd.tar.gz bs=512 skip=1 $ file *
Y con eso ya tendremos un archivo llamado main.cvd.tar.gz que tiene 512 bytes menos (los del inicio, la cabecera).
Ahora solamente tenemos que descomprimirlo como un tar.gz normal:
$ tar xfvz main.cvd.tar.gz $ file *
Y disfrutar de lo chunkeado y extraido 🙂
Saludos cordiales.