
Una forma bonita de encontrar archivos duplicados en Linux es usando find, sort, uniq y md5sum
Ejemplo:
$ find /home/fanta ! -empty -type f -exec md5sum {} + | sort | uniq -w32 -dD > /tmp/archivos-duplicados.txtSe ha de cambiar /home/fanta por tu home. Y se ha que quitar $ ya que eso solo lo pongo para indicar que ese comando lo lanzas con un user que no es root.
Cuando pongo # suele ser para indicar que se trata de un comando que has de ejecutar como root.
Lo interesante es que vamos a ordenar los resultados por el hash de 32 dígitos en hexadecimal que obtendremos al hacerle un md5sum.
El resultado lo vamos a tener en un archivo en /tmp/ llamado archivos-duplicados.txt
Interesante a tener en cuenta
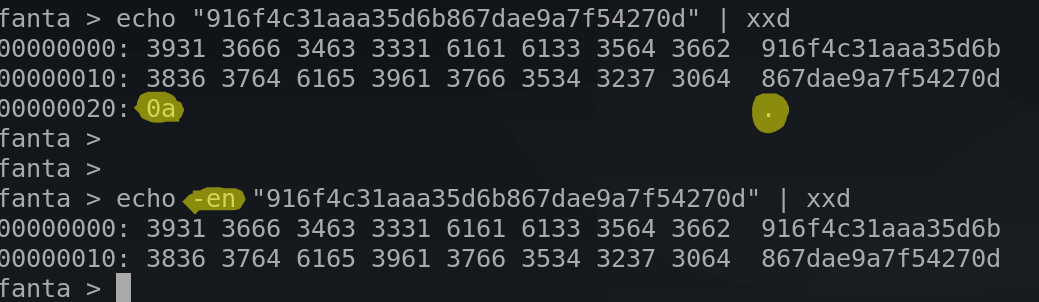
Si hacemos un echo de un hash md5 nos dirá que tiene 33 bytes:
$ echo "916f4c31aaa35d6b867dae9a7f54270d" | wc -c
33Pero es es mentira. La forma de hacerlo sería así:
$ echo -en "916f4c31aaa35d6b867dae9a7f54270d" | wc -c
32El motivo es que echo por defecto meterá un retorno de carro. Esto se puede ver así:
Y eso es todo lo que quería compartir.
Un saludo cordial.