

Vamos a ver varias formas para responder a estas 2 preguntas:
- ¿Qué procesos son los que están ahora mismo consumiendo más CPU?
- ¿Qué procesos son los que están ahora mismo consumiendo más RAM?
Respuestas rápidas:
La respuesta rápida cuando preguntan por CPU sería así:
# ps -A --sort=-pcpu --width 40 --format pid,user,pcpu,pmem,rss,vsz,comm,command | head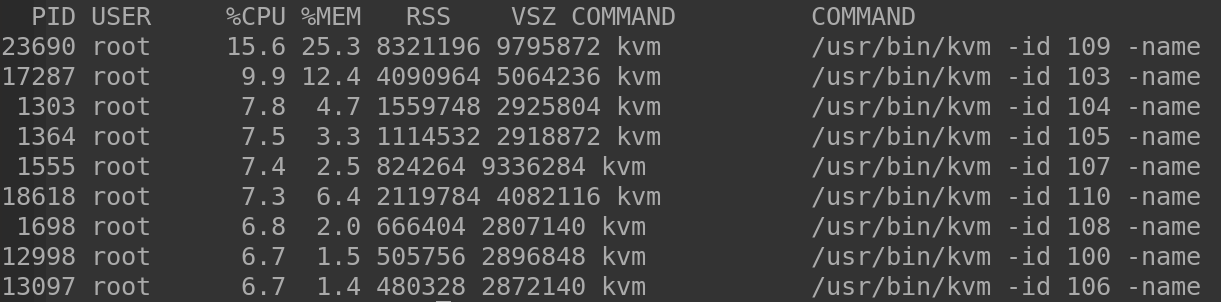
Ese ejemplo es una salida recortada. Se puede variar width a mayor tamaño si tenemos un comando largo de proceso. Por otro lado tambien se puede añadir a head -20 para ver el top 20.
La respuesta rápida cuando preguntan por RAM sería así:
# ps -A --sort=-pmem --width 40 --format pid,user,pcpu,pmem,rss,vsz,comm,command | headLa salida ahora saldría ordenada por -pmem (%MEM).
La respuesta lenta:
El motivo de incorporar las columnas VSZ (Virtual Memory Size) y RSS (Resident Set Size) es porque ambas nos dan información sobre cuánta memoria está usando un proceso.
VSZ es el tamaño de la memoria virtual. Este es el tamaño de memoria que Linux le ha dado a un proceso, pero no significa necesariamente que el proceso esté usando toda esa memoria.
Por ejemplo, muchas aplicaciones tienen funciones para realizar determinadas tareas, pero es posible que no las carguen en la memoria hasta que sean necesarias.
Linux utiliza la paginación por demanda, que solo carga páginas en la memoria una vez que la aplicación intenta usarlas.
El tamaño de VSZ que ve ha tenido en cuenta todas estas páginas, pero no significa que se hayan cargado en la memoria física. Por lo tanto, el tamaño de VSZ no suele ser una medida precisa de cuánta memoria está usando un proceso, sino más bien una indicación de la cantidad máxima de memoria que un proceso puede usar si carga todas sus funciones y bibliotecas en la memoria física.
RSS es el tamaño de memoria que un proceso está utilizado actualmente pero con matices.
A primera vista, puede parecer que el número RSS es la cantidad real de memoria física que utiliza un proceso del sistema. Sin embargo, las bibliotecas compartidas se cuentan para cada proceso, lo que hace que la cantidad informada de uso de memoria física sea menos precisa.
Ejemplo: Si tienes 2 programas de edición de imágenes (GIMP, KRITA) en el sistema, es probable que utilicen muchas de las mismas bibliotecas de procesamiento de imágenes. Si ejecutamos una de las aplicaciones, la biblioteca necesaria se cargará en la RAM. Cuando se abra la segunda aplicación, evitará volver a cargar una copia duplicada de la biblioteca en la RAM y simplemente compartirá la misma copia que utiliza la primera aplicación.
Para ambas aplicaciones, la columna RSS contará el tamaño de la biblioteca compartida, aunque solo se haya cargado una vez. Esto significa que el tamaño de RSS es a menudo una sobreestimación de la cantidad de memoria física que realmente está siendo utilizada por un proceso.
Por tanto lo más normal es que queramos ver ambas pero solo nos interese normalmente ordenar por -rss:
# ps -A --sort=-rss --width 40 --format pid,user,pcpu,pmem,rss,vsz,comm,command | headPor tanto si tienes una máquina que anda tirando de SWAP es buena cosa ver que procesos son los que más memoria están consumiendo. Muchas veces un meneo a tiempo de un apache, un tomcat, etc … permiten liberar sin tener que llegar a un swapoff -a ; swapon -a forzado.
Identificando los procesos que más consumen también podemos ver si realmente necesitamos algo más de recursos. Lo mismo es que necesitamos más memoria RAM por ejemplo.
Crear unos alias:
Añadir estos alias a .bashrc de nuestro user puede ser interesante para disponer de pcpu, prss y pmem a manopla:
alias pcpu="ps -A --sort=-pcpu --width 40 --format pid,user,pcpu,pmem,rss,vsz,comm,command | head"
alias prss="ps -A --sort=-rss --width 40 --format pid,user,pcpu,pmem,rss,vsz,comm,command | head"
alias pmem="ps -A --sort=-pmem --width 40 --format pid,user,pcpu,pmem,rss,vsz,comm,command | head"
Y eso es todo en esta entrada.
Saludos cordiales.