

Hoy he estado probando con Ale y Mari un software libre que permite convertir la voz en texto. Y no funciona nada mal.
DeepSpeech es un motor de software libre que utiliza un modelo entrenado gracias a técnicas de «machine learning». Está basado en el trabajo de investigación «Deep Speech: Scaling up end-to-end speech recognition» [1].
Lo que vamos a instalar nos permitirá procesar el audio de archivos en formato WAV y obtener su transcripción en texto plano (en archivos json por ejemplo).
Esto en cristiano es que si hablamos y decimos «sube el volumen» y le pasamos esa grabación a deepspeech, este será capaz de darnos de vuelta el texto de lo que acabamos de grabar.
Instalar DeepSpeech en GNU+Linux
Los pasos que podemos realizar para instalar esto en una Debian 10 son los siguientes:
# apt update && # apt upgrade -y
# apt install vim wget python3-pip curl -y
# pip3 install deepspeech
# deepspeech -hArchivos WAV de prueba
Una vez disponemos de deepspeech vamos a necesitar algunos archivos wav de prueba.
Es posible encontrar un buen dataset aquí: voice.mozilla.org/es/datasets
Aunque para esta prueba vamos a usar los que comparten desde el repositorio del proyecto. Se puede bajar desde línea de comandos así:
$ mkdir /root/mandanga
$ cd /root/mandanga
$ curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.6.1/audio-0.6.1.tar.gz
$ tar xfvz audio-0.6.1.tar.gz
$ rm audio-0.6.1.tar.gz Y con eso tendremos archivos wav de prueba en el directorio /root/mandanga/audio
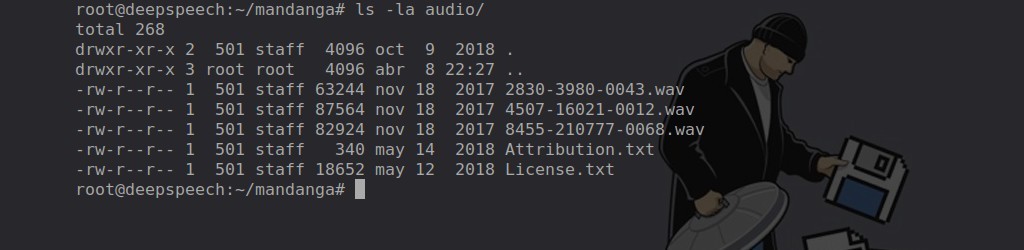
Descargar los modelos
Cuidado que ocupan casi 2 Gb. Puede que si dispones de una mala conexión esto tarde un rato bueno.
# cd /root/mandanga/
# curl -LO github.com/mozilla/DeepSpeech/releases/download/v0.6.1/deepspeech-0.6.1-models.tar.gz
# tar xfvz deepspeech-0.6.1-models.tar.gz
# mv deepspeech-0.6.1-models models
# rm -rf deepspeech-0.6.1-models.tar.gz
Ejemplos de uso
Un ejemplo de uso es este:
# deepspeech --model /root/mandanga/models/output_graph.pbmm --lm /root/mandanga/models/lm.binary --trie /root/mandanga/models/trie --audio /root/mandanga/audio/4507-16021-0012.wav
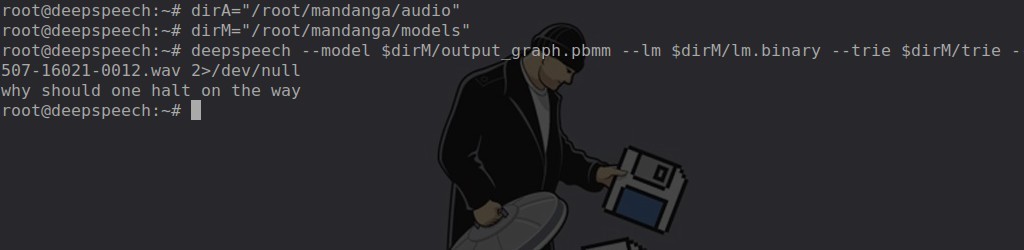
Ese archivo contiene un audio que dice «Why should one halt on the way» (¿Por qué debería uno detenerse en el camino?)
Documentación
Algo se puede ver aquí: deepspeech.readthedocs.io/en/v0.6.1/?badge=latest
Posibles usos
Por ejemplo para darle ordenes a algún cacharro. Para crear proyectos que puedan ser controlados por voz.
Para crear bots y meterlos en mumble, jitsi, …
Saludos cordiales.
—
[1] – Deep Speech: Scaling up end-to-end speech recognition – arxiv.org/abs/1412.5567